Mendelian Randomisation: A New Purpose for GWA Studies?
Many in quantitative genetics have been disappointed by the lack of clinical applications of GWA study findings. But perhaps genetic associations serve us in another way: they provide us with instruments for Mendelian randomisation, a method for disentangling causation from correlation in human population data.
In the last decade the genetics literature has seen a massive boom in the number of genome wide association (GWA) studies published. These studies use population-wide genetic data to look for associations between single nucleotide polymorphisms (SNPs) and human complex traits. To date, we have identified well over 100,000 SNP-trait associations through GWA studies.
One of the motivations for GWA studies was the utopian concept of precision medicine: where individual’s genotypes are used to tailor the treatment or preventative medical advice they receive. The hope was that this would improve outcomes for individuals. In reality, there has been very little uptake of genetics in the clinic outside of tests for Mendelian disorders. Polygenic risk scores developed from GWA results to facilitate precision medicine have proved to have very limited predictive ability.
Randomised control trials are the gold standard of medical research. They establish causality between a treatment and an effect through random assignment of individuals to treatment or control groups. In humans, randomised control trials are typically only performed with treatments that have been through rigorous safety testing and are backed by sufficient evidence that they will have positive health effects.
What if we are interested in a question like, say, how high body fat content affects risk of cardiovascular disease? There are obvious ethical problems with performing a randomised control trial in this case: we cannot instruct individuals to increase their body fat, knowing that might increase their risk of disease. Rather we are limited to the analysis of epidemiological data, from which we may be able to infer a positive correlation between the body fat and disease, but we could never definitively show that fat is the true cause of the increased risk of cardiovascular disease. There are plenty of confounding factors that could increase both the risk of cardiovascular disease and body fat content, such as consumption of a high fat diet.
Enter Mendelian randomisation. The premise of Mendelian randomisation is that we have all been randomly assigned to genotypes at conception, much like how we randomly assign participants in a randomised control trial to a treatment or control group. We can safely assume that genetic variants associated with some exposure, such as body fat content, in a well performed GWAS are linked to a causal variant. If there is a causal relationship between the exposure and an outcome, such as cardiovascular disease, then we expect that there will also be a relationship between the outcome and the SNPs that are causal for the exposure.
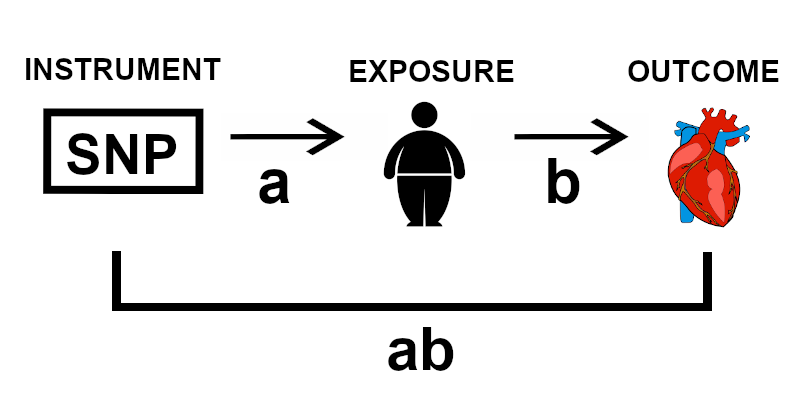
Figure 1 | Schematic demonstrating the basic concept of Mendelian randomisation, illustrating with the example of high body fat as an exposure and cardiovascular disease as an outcome.
Mendelian randomisation exploits this relationship and uses regression techniques to estimate the causal effect of the exposure on the outcome (b) from the effect of the SNPs on the exposure (a) and the effect of the SNPs on the outcome (ab) (Figure 1). Thus to perform Mendelian randomisation, we need strong instruments: SNPs that are good predictors of the exposure. To find such instruments, robust GWA studies are imperative.
Thus our GWA study findings have opened up a new and exciting research avenue. Mendelian randomisation will allow us to establish causal pathways in humans that we would otherwise have to infer from model organisms, whose biology does not always translate into humans. Directly studying a disease of interest in the human population is especially helpful for diseases which are difficult to model in other species. Lots of human disease exists in a web of comorbidity, where relationships between diseases are still poorly understood, so there are plenty of interesting pathways to be uncovered.
By understanding the causal relationships between exposures and outcomes, we can develop more effective interventions for prevention and treatment of disease. Although the application of Mendelian randomisation is still an area of active research, I hold much hope for its contribution to medical research.
This blog post was inspired by the Mendelian randomisation workshop provided at the European Mathematical Genetics Conference 2020. Many thanks to all of the organisers and contributors.
References
Buniello, A. et al. (2019) ‘The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019’, Nucleic Acids Research. Oxford University Press, 47(D1), pp. D1005–D1012. doi: 10.1093/nar/gky1120.
Bowden, J.; Spiller, W.; Sanders, E.; Richardson, T. & Mounier, N. (2020) ‘Mendelian randomization workshop’, European Mathematical Genetics Conference, virtual, 15th April 2020.