Useful Terminology for Submitting Jobs to a Supercomputer
The COVID-19 pandemic sees many research students who would normally have worked in the wet lab being asked to undertake computational projects. Oftentimes, these projects involve big data or computationally intensive simulations, and are thus carried out on university supercomputers. Students are typically given a crash course in how to use the command line, but are left in the dark about how these computers actually work. Here, I provide a tour of supercomputing terminology that will help new students better schedule jobs, understand documentation, and ask for help.
In layman’s terms, a supercomputer is just a very powerful computer. To give this some meaning, we have to discuss both what I mean by powerful and what I mean by computer. A computer is a device capable of carrying out arithmetic or logical operations, like adding up a series of numbers. It only requires two components to be able to do this: processor(s) (to perform operations - like addition) and memory (to store the data it is working with - like the numbers it is adding up). ‘Powerful’ is an imprecise way to imply that supercomputers can carry out operations very quickly or with large quantities of data that would be unworkable on your standard laptop or PC. In reality, a supercomputer is a collection of many computers that work together to achieve this. We call each computer in this collection a node.
When you log on to a supercomputer, you are actually logging onto an interactive node. An interactive node is a computer you can use to communicate with the supercomputer via a batch scheduler like SLURM or Sungrid Engine. You tell the batch scheduler what you need done (using a jobscript), and it will go and get the supercomputer to do the job you have asked. The batch scheduler ensures that the resources of the supercomputer are used efficiently.
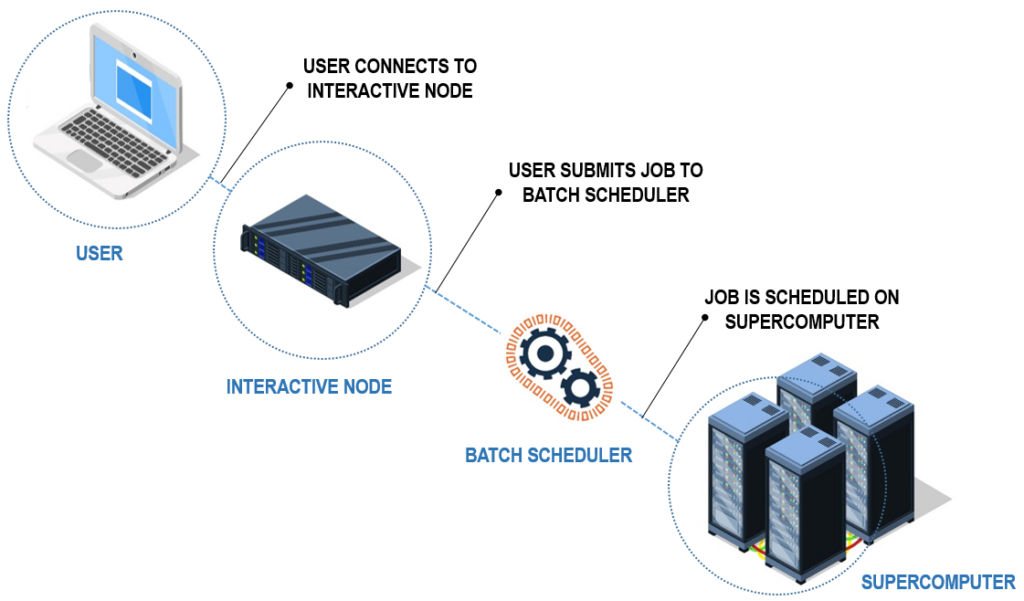
When submitting a job to a supercomputer, you will need to specify the number of processors and the quantity of memory you would like. These processors are typically referred to as cores. You can think of it like a person - capable of doing one operation at a time, like adding two numbers together. Therefore, the more cores you have, the more that you can do at once. This is the basis of parallelisation: breaking a task down into smaller chunks that can be done independently by different cores at the same time.
Most modern laptops and PCs have multiple cores. These cores share most of the memory on the device, but also have a small amount of memory that is just their own (called a cache). Memory is where data is stored: you can think of it like a warehouse. Each item in memory is indexed with an address. If a core needs to know something, it could go to the relevant address and have a look at what’s stored there. However, this causes problems if all of our cores want to access the same bit of memory at the same time. We’ll end up with a queue of cores waiting to visit a certain address. To prevent this, it is the job of the memory bus to manage the exchange of data from the core to memory and vice versa.
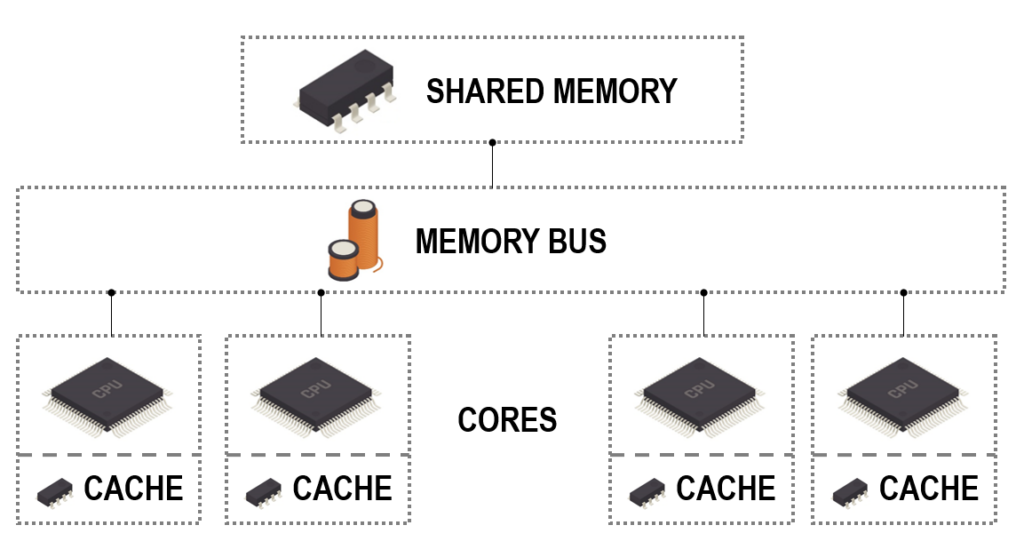
If we ask each core to add up the same numbers at the same time, each core will retrieve the relevant data from the memory bus. Each core can record its own subtotal in its cache until it is done adding up all of the numbers it has been assigned. This design is called shared memory architecture, because all cores share memory.
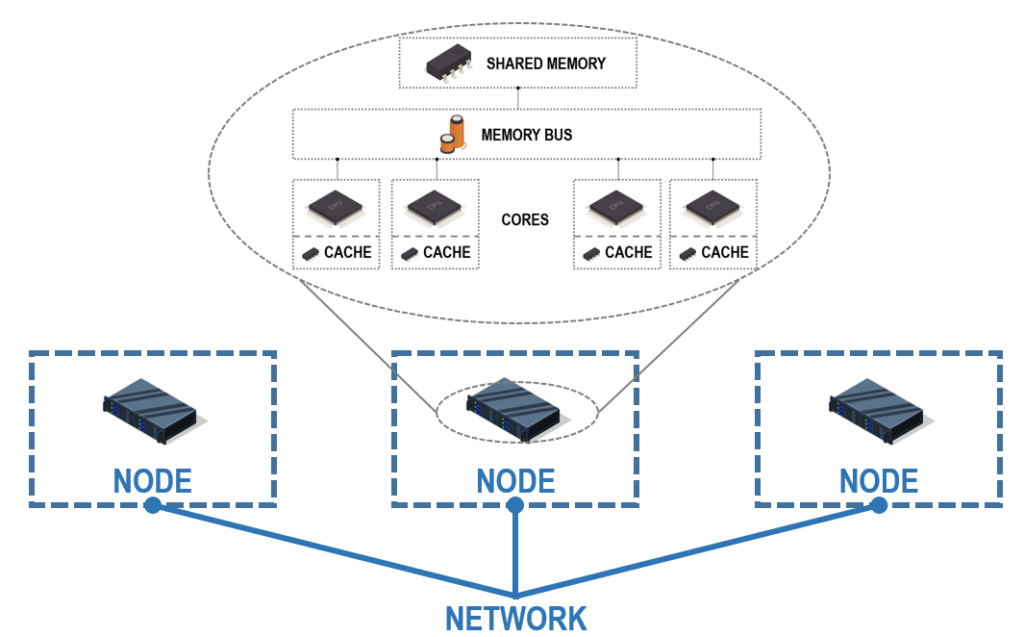
However, supercomputers often have 100s or 1000s of cores, so shared memory architecture becomes unfeasible. Instead, supercomputers chain many computers (nodes) together. These nodes communicate through a network. Each node has its own memory shared between its cores, but this memory cannot be accessed by the core of any other node. This is known as distributed memory architecture.
So, when requesting resources (cores and memory) for a job, first look at what your supercomputer has available. As an example, imagine the table below gives the specifications of a supercomputer. This supercomputer is has 71 nodes. Each of these nodes has 16 cores, and thus the supercomputer has 71 * 16 = 1136 cores altogether. Each node has 64 GB of memory, shared between its 16 cores. You will usually specify memory per core, and as only one person can use a core at a time, if this was all your supercomputer had you might as well request 64 / 16 = 4 GB of memory per core. In reality, your supercomputer probably has different types of nodes with different numbers of cores or memory per core, so you can request what best suits your job.

Asking for multiple cores offers no benefit to your job if it cannot be run in parallel. The software you’re using may offer parallelisation, or if you’re writing your own scripts you can build this in. Parallel computing requires communication between cores, which is carried out differently in shared memory and distributed memory architectures. The programming model used for shared memory architecture is shared variables, and the model used for distributed memory architecture is called message passing.
I won’t go into the details of these models, but it is useful to know how they are managed. Say you want 8 cores in the fictitious supercomputer I described above. This is a case for shared memory, because we only want a subset of cores on a single node. You submit a job which involves running a parallelised program. This is allocated to a core called the boss worker. The boss then instructs the other requested cores to begin running their own copy of the program. These copies are known as threads. All of the threads share the same memory as the boss because they are part of the same node. The software that manages this division of labour is called OpenMP.
However, if you wanted to use 32 cores in the fictitious supercomputer, you’ll need two nodes, and therefore must adopt a message passing approach to parallelisation. The message passing interface (MPI) library is a collection of functions that allow different nodes to communicate effectively by sending each other packets of data called messages. In message passing, we refer to each copy of the program as a process rather than a thread, because it runs independently without sharing memory. Threads can be seen as being a segment of a larger process.
Finally, there is one last way to parallelise your job - job arrays. Job arrays are used to run many, very similar tasks at one time. Importantly, these tasks do not depend on each other. OpenMP and MPI are sophisticated and can deal with much more complex tasks because they mediate communication between cores. An example of a task suitable for an array job would be running an analysis multiple times with different parameters and storing the outputs.
Hopefully now you have a better understanding of the jargon used when talking about supercomputers. Below, I summarise the key terms:
| Term | Definition |
|---|---|
| Core a.k.a CPU-core, processor | Electronic circuitry that executes instructions from a computer program |
| Node | A device within a network |
| Network | A group of devices that communicate with each other |
| Interactive node | The node which a user accesses to submit jobs to the batch scheduler |
| Batch scheduler | A computer application for controlling the execution of jobs |
| Job | A task to be performed |
| Jobscript | A set of commands and resource requirements submitted to the batch scheduler |
| Parallelisation | Carrying out multiple operations simultaneously |
| Shared memory architecture | All cores are connected to the same piece of memory. |
| Distributed memory architecture | All nodes have their own memory. |
| OpenMP | Software facilitating parallelisation on shared memory architecture |
| MPI | Software facilitating parallelisation on distributed memory architecture |
| Thread | A part of a process |
| Process | An instance of the execution of a computer program |
| Job array | A collection of similar jobs submitted to the batch scheduler simultaneously |
If you’re interested, I highly recommend the free course provided by the Edinburgh Parallel Computing Centre at this link. This course goes into more detail, mentioning things I have missed out like GPUs and NUMA nodes. It also gives exciting examples of how supercomputing is used for simulations.